Table des matières
Le Web scraping : extrayez automatiquement des données web
Vous avez certainement déjà eu besoin d’extraire des données présentes sur un site web. Que ce soit pour comparer des prix ou pour récupérer des articles de blog, la collecte d’informations peut devenir nécessaire. De plus, se constituer une bonne base de données est un atout formidable pour des activités aussi diverses que la prospection, la veille concurrentielle ou bien encore l’analyse de votre clientèle.
Mais parcourir le web au hasard, en effectuant manuellement des copier-collers, devient vite monstrueusement chronophage ! Heureusement, le web scraping vous permet d’automatiser la récupération de données de manière intelligente et rapide, partout sur le web.
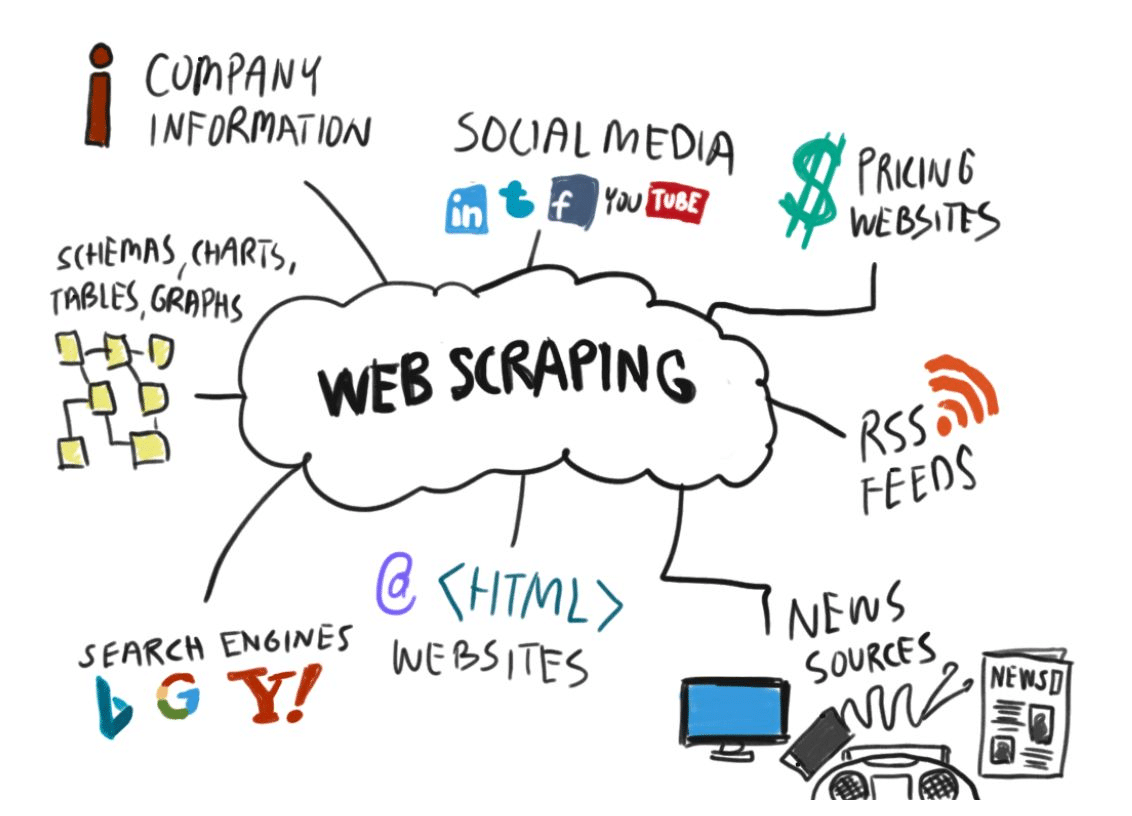
Qu’est-ce que le web scraping ?
Si l’on s’en tient à la simple traduction, le web scraping a pour définition : « grattage de web ». L’image est parlante, mais elle mérite toutefois d’être expliquée plus en détails. Le web scraping consiste tout simplement à collecter des données sur le web, de façon rapide et automatique. Pour cela, vous pouvez construire votre propre outil (le scraper) à l’aide du langage de programmation Python.
Si les joies du langage informatique vous laissent insensible, vous pouvez avoir recours à des solutions prêtes à l’emploi. Il peut s’agir d’extensions de navigateurs web ou de logiciels qui se prennent en main de manière intuitive. Les frameworks (sorte d’ossatures de logiciels) vous permettent quant à eux d’adapter votre manière de faire pour votre scraping web.
Une fois que vous avez adopté l’outil et la façon de procéder qui vous conviennent, le web scraping peut commencer. L’opération se passe en deux temps :
- Votre scrapeur extrait le code HTML de la page que vous visez. (les données sont alors « siphonnées » de façon brute et déstructurée)
- L’outil restructure vos données et les classe dans un fichier ou dans une base de données
Tout cela pourrait ressembler à des méthodes similaires à du piratage, mais il n’en est rien. La plupart des données mises à disposition sur les sites web sont publiques. Les récupérer à des fins personnelles n’a rien d’illégal. Nous verrons toutefois plus loin qu’il y a quelques limites à respecter dans votre pratique du web scraping pour ne pas risquer d’enfreindre la loi.
Voici une liste non exhaustive des bénéfices que vous retirez du web scraping :
- Vous récoltez des données de façon bien plus rapide qu’en le faisant « à la main »
- Ces données sont récoltées automatiquement d’après des paramètres que vous avez définis
- La bonne structuration finale vous permet d’exploiter toutes ces infos et de les appliquer à de multiples usages
Web scraping : les applications concrètes
Le web scraping au service de votre veille concurrentielle
Dans la surveillance de l’activité des concurrents, il y a de grands besoins de données. Plus vous récoltez d’informations sur la réputation d’une entreprise et sur les prix qu’elle pratique, plus vous avez une idée précise de son activité.
D’ailleurs, vous pouvez tout à fait appliquer la méthode du web scrapping à votre propre entreprise. C’est un outil formidable pour avoir un aperçu concret de votre réputation.
Suivre l'actualité
Aujourd’hui, chaque entreprise est étroitement liée à l’actualité. Dans nos sociétés, les événements sont interdépendants les uns des autres. Il est donc important d’avoir en permanence une vue d’ensemble de ceux qui sont susceptibles d’impacter votre activité. Grâce au web scraping, vous centralisez en un seul endroit les actualités récentes qui vous intéressent.
Boostez votre marketing par emails
La collecte de données est précieuse dans vos campagnes par email. En scannant des annuaires professionnels comme Linkedln ou Les Pages Jaunes, votre outil de scraping va extraire des informations utiles. Adresse postale, adresse email, actualité des entreprises…
Vous vous constituez une base de données solide pour démarcher de nouveaux prospects.
Le web scraping pour vos études de marché
Récupérer des données partout sur le web est une démarche indispensable à une bonne étude de marché. Vous établissez une vue d’ensemble des différents profils de consommateurs, ainsi que de leurs habitudes et de leurs besoins. Vous disposez ainsi d’informations pertinentes sur lesquelles construire votre stratégie.
Le SEO
Le SEO (Search Engine Optimisation) est une pratique indispensable pour faire apparaître votre site en bonne place dans les résultats de recherche Google. Le web scraping vous simplifie énormément la tâche : faites une veille sur les mots-clés importants ou recherchez les pages 404 sur vos sites de façon totalement automatisée.
Et dans le domaine de l'IA ?
Mettre au point une intelligence artificielle est un travail de titan ! Pour fonctionner de façon autonome, la future IA a besoin d’énormément de « matière » de laquelle se « nourrir ». Plus vous lui apportez de données pertinentes sur lesquelles travailler, plus votre IA se développe.
Le web scraping permet de nourrir votre intelligence artificielle en continu avec un flux d’informations gigantesque.
Comment fonctionne le web scraping ?
Le web scraping s’effectue en deux temps. Tout d’abord, votre programme parcourt le web à la recherche des sites qui contiennent les données dont vous avez besoin.
Dans un second temps, les données sont extraites de chaque site et sont organisées sous une forme structurée que vous pouvez exploiter. La partie « reconnaissance » est effectuée par le web crawler. Une fois que ce dernier a repéré les sites pertinents, le web scraper entre en action pour extraire les données et pour vous les restituer de façon lisible.
Le web crawler
Les web crawlers sont aussi connus sous le nom de « spiders ». Ce sont des intelligences artificielles à qui vous ordonnez de repérer des sites. Les crawlers recherchent les sites en fonction des spécificités que vous leur avez précisées.
Dans le processus de web scraping, ce sont un peu les « éclaireurs » qui balisent le terrain pour que les web scrapers puissent venir ensuite extraire les données. Les web crawlers ne sont pas uniquement destinés au web scraping. Google, par exemple, utilise ce type de robots pour parcourir le web dans le but de lire et d’indexer tous les sites.

Le web scraper
Dans la seconde étape du web scraping, le web scraper va extraire les données sur les sites balisés par le web crawler. Pour ce faire, il parcourt la structure HTML du site. Le langage HTML est ce qui permet d’afficher aux visiteurs la partie visible d’une page, notamment le texte, les sites et les paragraphes.
Si vous êtes à l’aise avec la programmation, vous pouvez construire votre propre scraper à l’aide du langage Python. Sinon, des logiciels ou des extensions de navigateurs vous permettent d’effectuer du web scraping sans connaissances particulières.
De même, vous pouvez choisir d’effectuer du web scraping à partir de votre propre PC (en « local ») ou à partir du Cloud. Scraper à partir du Cloud vous fait économiser les ressources de votre ordinateur. Il faut savoir que le web scraping est gourmand en énergie et pourrait monopoliser votre machine pour plusieurs heures si vous le lancez en local.
Vous souhaitez profiter d'une démo personnalisée avec un expert ?
Les limites du web scraping
Faire ses premiers pas en web scraping peut être grisant, voire franchement amusant ! Toutefois, vous allez découvrir assez rapidement que ce nouveau « super pouvoir » a également ses limites. Rassurez-vous, rien qui puisse contrarier vos projets, à condition de prendre les bonnes mesures pour palier aux difficultés.
Les pages web changent leur structure HTML
Eh oui, c’est ce qui est embêtant avec les bons webmasters : ils mettent constamment leurs sites à jour. Votre scraper a été calibré pour extraire les données d’une page web à un moment T.
Le moindre changement dans le code HTML va donc mettre en échec votre web scraping. Pour éviter que votre collecte de données n’avorte, vous devez modifier régulièrement votre scraper pour l’adapter à la nouvelle structure de la page visitée.

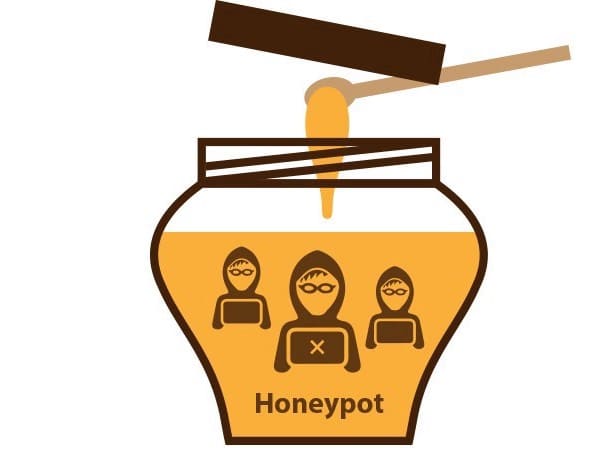
Les Pièges (HoneyPots)
Là, nous entrons dans ce qui s’apparente au jeu du chat et de la souris. Certains sites web ne désirent pas subir de scraping. Ils vont donc piéger votre scraper avec de « faux » liens qui signaleront immédiatement votre présence, dans le but de bloquer éventuellement votre adresse IP.
Un autre moyen astucieux qu’ont trouvé les sites pour vous mettre en déroute est de « perdre » votre scraper. Ils lui feront prendre le chemin d’un lien menant à une arborescence sans fin, le faisant ainsi travailler en pure perte.
Les paramètres du scraper sont trop vagues
Lors de vos premiers essais, il est très probable que vous n’indiquiez pas de façon assez précise au scraper ce qu’il doit extraire. Résultat : vous allez vous retrouver avec une masse indigeste de données inutilisables.
Heureusement, la pratique vous apprendra rapidement à « communiquer » avec votre outil de web scraping pour lui faire faire ce qu’on attend de lui : vous faire gagner du temps et de l’énergie.
Quels sont les outils de web scraping ?
Le langage Python : la base du web scraping
Construire un outil de web scraping avec Python permet de disposer d’une solution entièrement personnalisée. Le langage Python est très facile à apprendre. Si vous n’êtes pas familier de la programmation, mais que vous désirez vous initier, Python est le langage idéal pour commencer.
Parmi les librairies Python pour le web scraping, il est d’usage d’associer Requests et BeautifulSoup. Les deux se complètent à merveille et vous donneront un outil de web scraping optimal.

Les extensions de navigateurs
Les extensions (aussi appelées modules complémentaires) vous donnent la possibilité de faire du web scraping directement depuis votre navigateur web. Web Scraper est l’une des plus connues. Développée pour Chrome et Firefox, elle permet d’extraire un nombre impressionnant de données à partir des pages web.

Les logiciels
Vous pouvez également scraper un site avec un logiciel installé sur votre ordinateur. Les logiciels demandent une prise en main plus poussée que les extensions de navigateur. En revanche, ils permettent une utilisation plus avancée dans le cadre du web scraping. Parmi les plus performants, citons :
- Parsehub
- Heluim Scraper
- Octoparse
Quelques solutions SaaS pour le web scraping
L’avantage des solutions SaaS est qu’elles sont basées dans le Cloud. Vous n’aurez donc pas de phénomène de surcharge sur votre ordinateur. De plus, les outils en ligne sont régulièrement mis à jour sans que vous ayez à vous en préoccuper.
PhantomBuster

Ce logiciel Made in France va devenir indispensable à vos campagnes de prospection. C’est un scrapeur complet et performant qui vous fait économiser des milliers d’heures de travail en réunissant pour vous les données présentes sur le web.
Reply

Tout l’attrait de Reply est que vous disposez au même endroit d’un scraper et des outils nécessaires au marketing mail. Vous pouvez, dans un même mouvement, récolter automatiquement les adresses de nouveaux prospects puis les intégrer dans votre campagne de cold-mailing.
Snov.io

Snov.io centralise également les activités de scraping et de cold-mailing. Le logiciel va encore plus loin en intégrant le tout à un CRM qui vous permet d’avoir une vue globale de vos activités.
Et la loi dans tout ça ?
Nous l’avons vu, le scraping de site web est une méthode qui démultiplie le potentiel de vos activités. Légalement, il est tout à fait autorisé de récolter des données sur le web. Il faut toutefois faire attention à certaines choses.
Par exemple, toutes les données d’un site ne sont pas libres. Certaines sont soumises à la propriété intellectuelle et d’autres, comme les données personnelles, sont jugées confidentielles et ne peuvent donc pas être extraites.
- Lorsque vous arrivez sur un site, dirigez automatiquement votre scraper vers le fichier robot.txt du site. Si le propriétaire refuse que vous extrayiez tout ou partie des données, il l’indique dans ce fichier.
- D’autre part, c’est une bonne idée d’aller voir les conditions de service des sites sur lesquels vous projetez de faire du web scraping. C’est à cet endroit que vous êtes susceptible d’être informé de la politique du site vis-à-vis de l’extraction de données.
- Enfin, veillez à ne pas envoyer trop de requêtes sur un même site. Si vous le surchargez, cela risque de le faire planter. Non seulement cela fait échouer votre tentative de scraping, mais vous avez toutes les chances d’être considéré dorénavant comme un indésirable sur le site.
Vous souhaitez profiter d'une démo personnalisée avec un expert ?
